Applying markup to translations in Angular applications (the right way)
Daan Scheerens - Jan 11, 2021
Adding multi-language support to an application nowadays is easy! Many frameworks offer out-of-the-box support, and if not, then there are usually a bunch of 3rd party libraries available. It is just a matter of picking the one that best fits your internationalization requirements.
So, what about Angular? Basically, you get to choose between:
Angular i18n - Angular's native solution
NGX-Translate - The first and most commonly used translation library for Angular
Transloco - A more modern translation library for Angular
Each has its pro and cons. However, regardless of which one you choose you will ultimately run into something which has not been properly addressed in any of these: markup. So, what do I mean with markup? Bold text, italic text, links, icons, etc., basically anything that is not text itself but should be part of the translation and influences the rendered output.
Dealing with markup in translations the naive way
The next examples all make use of Transloco, simply because (in my opinion) it is the best option currently available. Fortunately, the Transloco API and translation concepts are quite similar to that of ngx-translate. Most of the examples can thus easily be mapped to ngx-translate.
Suppose you're building an application that greets the user with a welcome message once logged in. In the English translation file, you might have the following entry:
1 2 3{ "GREETING": "Hello {{ name }}, nice to see you!" }
Nothing fancy here. All is working just fine, but then the visual designer asks if you could have the name displayed in a bold font. Hmmmm, there goes your nice and clean translation setup!
So, how do you implement this requirement? Unfortunately, none of the translation libraries offers a good solution for this. In practice I've seen developers (myself included) solve it in two different ways.
Markup via translation splitting
The first method is to slice the text into segments that are individually styled. For the greeting message three parts can be identified:
1 2 3 4 5 6 7{ "GREETING": { "1": "Hello ", "2": "{{ name }}", "3": ", nice to see you!" } }
Within the template of a component that displays the greeting you would need to write something like the following:
1 2 3 4 5<h2> {{ 'GREETING.1' | transloco }} <strong>{{ 'GREETING.2' | transloco:{ name: user.firstName } }}</strong> {{ 'GREETING.3' | transloco }} </h2>
Although this gets the job done, it is not exactly an elegant solution. Both the translation file and the component template have gotten more verbose.
Apart from the lack of elegance, this approach has an even bigger problem: it is not a sustainable solution for every language. Languages have different grammars, so the order in which certain parts are placed might not match with that of the language that was used to split the message. The chance of this being a problem for a particular language increases with the number of segments. Especially if each segment is styled differently.
A consequence of this approach is that it might be hard or even impossible to define correct translations for certain languages.
Markup via an innerHTML-binding
Because of the problems you face when using the translation splitting approach, most developers favor another method: innerHTML-binding. In fact, that is what the Transloco documentation recommends. The idea of this method is quite simple: markup is encoded in the translation files using regular HTML elements. For the greeting message shown earlier, the entry in the translation file would look like this:
1 2 3{ "GREETING": "Hello <strong>{{ name }}</strong>, nice to see you!" }
And within the template you would write the following:
1<h2 [innerHTML]="'GREETING' | transloco:{ name: user.firstName }"></h2>
Obviously, this is much cleaner than the translation splitting approach. It also doesn't suffer from the issue that the order in which certain parts appear in the message can be language dependent. After all, a translator has direct control over where the markup tags are placed.
Great! So, that settles it, right?
Well, not quite. Unfortunately, the innerHTML-binding approach also has some problems.
Firstly, there is the issue of markup injection. Even though Angular will shield you from XSS attacks when using an innerHTML-binding, there is still a possibility that an interpolated section in your translation contains malicious content which is not stripped. This is illustrated in the example program below:

In this example you can see that the user is able inject a link in the rendered translation. Fortunately, this is just a link to a harmless website and doesn't affect anybody outside of the user that manually enters this link in the input field. However, you can imagine how this could easily abused if the input would also be displayed for other users of the application. An user with evil intentions could enter a text with a link to lure other users to a malicious website.
Markup injection only is a problem if the translation text contains an interpolation expression. If this is the case, it can pose a serious security risk. The problem can be addressed by sanitizing the input values, e.g. by escaping certain characters with HTML entities.
Another issue with the innerHTML-binding approach is that it can add a lot of clutter to the translation values. This is clearly illustrated by the following (real life) example:
1 2 3{ "SCHEDULED": "Scheduled task <a href=\"{{ taskUrl }}\">{{ taskLabel }}</a> for <a href=\"{{ resourceUrl }}\">{{ resourceName }}</a> on <a href=\"{{ dateTimeUrl }}\">{{ dateTime }}</a>" }
The translation above is used to show a notification message that contains three links. Can you easily spot what the message is saying? Probably not!
Due to the vast amount of HTML markup the actual message becomes obscured. If we as developers already have trouble reading this, imagine how this would look like for a translator with a non-technical background: a soup of characters! Errors can easily slip into such translation values, breaking either the text, the HTML syntax or both.
Finally, yet another problem with innerHTML-binding is also illustrated by this example. The links used within message are supposed to be links to routes within the application. Normally you would use the routerLink-directive for this purpose. However, you cannot use Angular components and directives in an innerHTML-binding. So, this means the links will behave like normal links and clicking them will cause the browser to load the links as if you would navigate to a different website or application. Consequently, the whole application reloads, which does not result in a very pleasing user experience (to say the least).
Note that there is actually a way of getting router links to work with the innerHTML-binding approach. This can be achieved using Angular Elements to create your own router link custom element. Doing so, however, is quite convoluted and comes with its own set of quirks.
Introducing contextual markup tokens
Clearly the translation splitting and the innerHTML-binding approaches are far from ideal solutions when it comes to dealing with markup in translated text. If these aren't, then what would be a better solution? This question can best be answered by looking at how we want the translations to look like. When we take the last translation example and reduce the message format to a bare minimum, we'll end up with something like:
1 2 3{ "SCHEDULED": "Scheduled task [task] for [resource] on [dateTime]" }
That is definitely much more readable than before. A translator would have a much easier job to translate the above than the version that was scrambled with HTML markup.
So, what did we actually do here? Well, we simply introduced our own special markup tokens: [task], [resource] and [dateTime]. At runtime, the application should substitute these tokens with a link and label for the corresponding entities.
What makes these tokens special is that they were conjured up specifically to be used within the context of this particular message. Applying this approach to other translations means that we should stop using a generic markup language (HTML) and instead use one that can be tailored for each translation individually.
This approach not only allows for simplification of the markup syntax, but it also allows fine grained control over what markup should be available for specific translations. A translator gone rogue therefore wouldn't be able to apply arbitrary (undesired) markup to translations.
Contextual markup in practice
Contextual markup, as shown in the example of the previous section, looks promising. However, there is a slight problem: the markup syntax is fictional! Transloco doesn't recognize it, Angular doesn't and the browser certainly doesn't either.
Alright, so that means we must teach them how!
Let's first decide on the right vessel for rendering such translations. Ultimately, the translation with markup needs to be rendered as a (sub)tree of DOM nodes. In Angular that is what components are meant for, so it makes sense to create a component for displaying translation values with contextual markup. We'll refer to this component as the translate component. Usage of the component in a template would look like:
1 2 3 4 5<translate [key]="'EXAMPLE_MESSAGE'" [params]="{ paramKey: 'value' }" [context]="exampleMessageContext" ></translate>
As can be seen in the example, the translate component accepts the following input:
The translation key which will be used to lookup the actual translation value for the active language.
Optional translation parameters that are used in interpolation expressions in the translation values.
A context that defines the custom markup syntax and rendering logic.
The first two of these inputs should be familiar if you've worked with Transloco or ngx-translate before. It is the context input that is new. Our translate component should be able to use this context input to parse the message and convert that to a set of DOM nodes. Together those DOM nodes form the rendered version of the translation value.
Parsing & rendering contextual markup
One of the challenges with the contextual markup is that the syntax can be anything. This means we cannot write a parser based on a predefined grammar. Also, it would be nice if the context could be defined via composition: mixing a set of different (reusable) parsers together.
How would such a parser look like? Well let's start with the basics: a parser should be able to transform (part of) a given translation value into a DOM node:
1type TranslationParser = (translationValue: string) => Node;
But what about the translation parameters? Those could be factored in as a second parameter for the parser function. However, that implies parsing the translation value again for every change in the parameters. A waste of effort since the structure remains the same! So, a better option is not to return a DOM node, but a render function that given the translation parameters returns a DOM node:
1 2 3type TranslationParser = (translationValue: string) => TranslationRenderer; type TranslationRenderer = (translationParameters: TranslationParameters) => Node;
Since we prefer a compositional setup with multiple parsers, this means that a single parser will not be responsible for parsing a translation value along its entire length. Instead, a parser will only process a portion of the translation value, while the others take care of the rest. To accommodate for this requirement the parser function should be modified to accept an offset that specifies the position within the translation value where the parsing should start. In addition, it should also return how many characters were parsed, so the next parser can continue at the next unparsed position.
If a parser is invoked at a position where it cannot parse the translation value, then it cannot return a render function. In that case returning undefined is the most logical choice. Adapting the parser model for the above results in the following:
1 2 3 4 5type TranslationParser = (translationValue: string, offset: number) => TranslationParseResult | undefined; type TranslationParseResult = { renderer: TranslationRenderer; parseLength: number }; type TranslationRenderer = (translationParameters: TranslationParameters) => Node;
The parser model is almost complete. One final missing ingredient is support for recursive parsing: we might need to support a syntax that can repeat itself (or that of other parsers). Such support is necessary to parse the following example translation value:
1[color:red]Don't click the [color:blue]blue[/color] button![/color]
In this example color blocks are used, where the parser would need to run the whole contents between the opening and closing color tags through the complete set of parsers. To put this in other words: a parser might need another parser function as parameter to parse the contents. This leads to the final model for translation parsers:
1 2 3 4 5 6 7 8 9 10type TranslationParser = ( translationValue: string, offset: number, parseContent: TranslationParser ) => TranslationParseResult | undefined; type TranslationParseResult = { renderer: TranslationRenderer; parseLength: number }; type TranslationRenderer = (translationParameters: TranslationParameters) => Node;
Returning to the translate component presented earlier, one of its input properties is the context, which is responsible for parsing and rendering the translation values. With the parser model above we now can define a model for this context: a sequence of translations parsers, i.e.: TranslationParser[];
Having defined the context for the translate component the next thing we need is a method for parsing translation values. This component should be able to do the following: given a translation value and the context as input, produce a sequence of render functions. The code below shows one way to implement this.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25function parse(translation: string, parsers: TranslationParser[]): TranslationRenderer[] { const parseContent = createCompositeParser(parsers); const renderers: TranslationRenderer[] = []; let offset = 0; while (offset < translation.length) { const parseResult = parseContent(translation, offset, parseContent); if (parseResult) { renderers.push(parseResult.renderer); } offset += parseResult?.parseLength ?? 1; } return renderers; } function createCompositeParser(parsers: TranslationParser[]): TranslationParser { return (translationValue, offset, parseContent) => parsers.reduce<TranslationParseResult | undefined>( (result, parse) => result ?? parse(translationValue, offset, parseContent), undefined ); }
Looking at the code above we can see that the parse function first folds all translation parsers into a single parser using the createCompositeParser utility function. The composite parser simply returns the TranslationParseResult of the first parser that does not return undefined. Then, the parse function iterates over the input translation value and keeps applying the composite parser. Every time a new parse result is obtained, the render function is added to the renderers array and the next parse offset is incremented with the number of characters that were parsed. If for some reason no parser was able to yield a parse result, then the current character is ignored and it simply continues with the next character. This process continues until the entire translation value was parsed. By the end all render functions have been collected and are then returned as result of the parse function.
Just having a sequence of rendering functions alone is not sufficient to actually display the translated texts (including markup). So, the translate component needs to perform one final step: invoke the rendering functions with the translation parameters and append the resulting DOM nodes the root element of the component:
1 2 3 4 5function render(target: Element, parameters: TranslationParameters, renderers: TranslationRenderer[]): void { for (const render of renderers) { target.appendChild(render(parameters)); } }
There you have it. With this approach the contextual markup syntax for translations can be realized. There are still a few small details to fill in to make this a complete solution. Mainly how the different parser functions look like. Although those remaining parts are not too complicated, they are out of scope for this article.
ngx-transloco-markup
Should you be interested in a complete solution then you can take a look at the ngx-transloco-markup library which implements the concepts outlined in the previous section. This library is an extension for Transloco that introduces a <transloco> component, which assumes the role of the previously presented translate component.
In this library parsers are called transpilers. They can be defined at different scopes within the application:
At transloco component instance level, via a parameter
Via the component injector
Via the module injectors
Together, these are folded into a sequence of transpilers by the transloco component to support a compositional style for defining the markup context for translation values. It comes prepacked with a small set of standard transpilers for bold markup, italic markup, and links. Those support most of the translation markup requirements.
Note that those standard transpilers use a generic syntax, while this article advocates a context specific syntax. So, the library therefore also provides a set of building blocks and link transpiler factories to easily create your own context specific transpilers.
Due to the extensible transpiler architecture it is quite easy to setup a fully tailored syntax for your translation values, thereby avoiding the problems of the naive translation splitting and innerHTML-binding approaches.
It also addresses the need for router links by making the rendering of links extensible. Due to the direct dependency on the @angular/router NPM package, support for such links has been moved to a separate library: ngx-transloco-markup-router-link. This library can optionally be included if your application requires this type of links in translated text.
A demonstration of ngx-transloco-markup in action is shown below. You can also view the demo application for yourself at the following StackBlitz project: https://stackblitz.com/edit/ngx-transloco-markup-demo
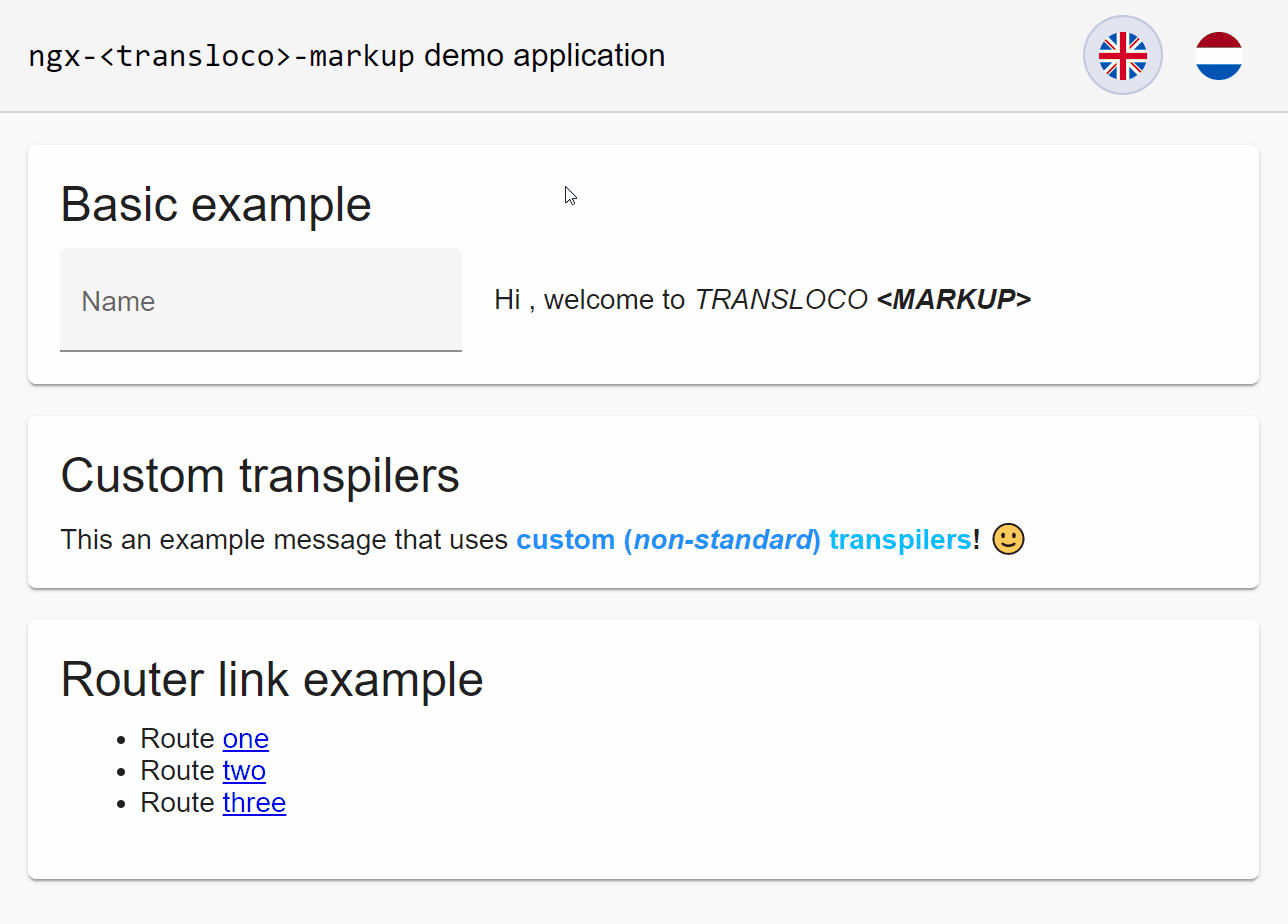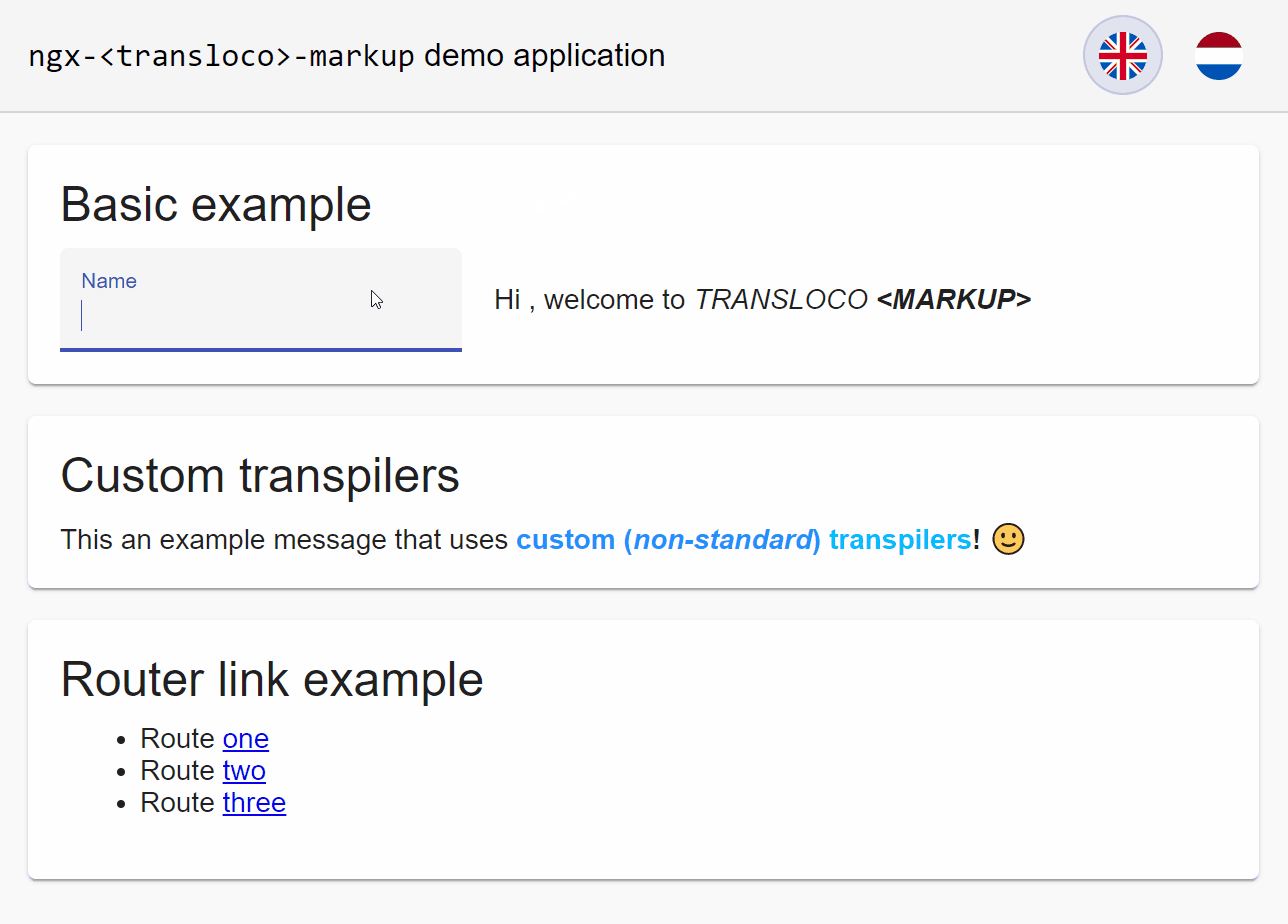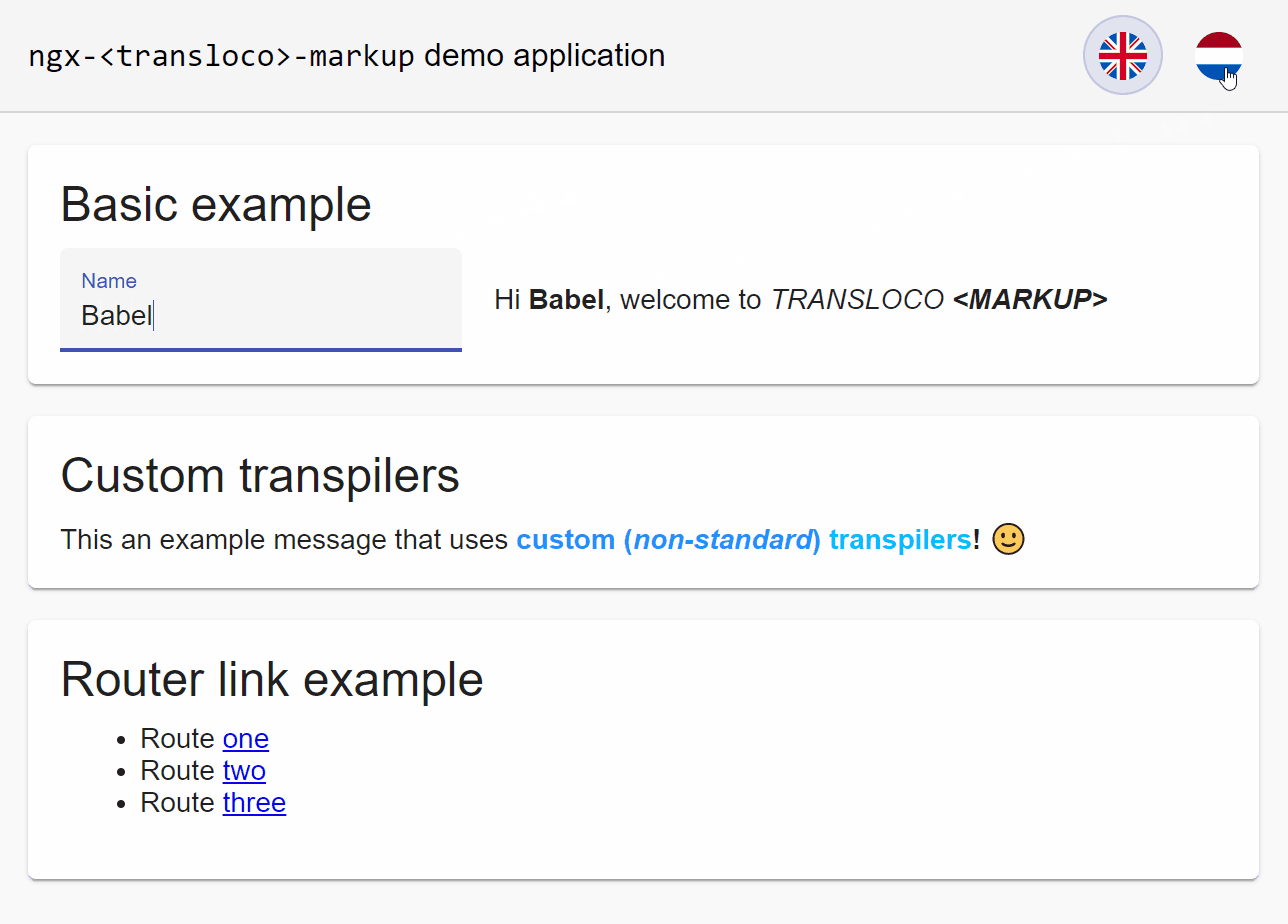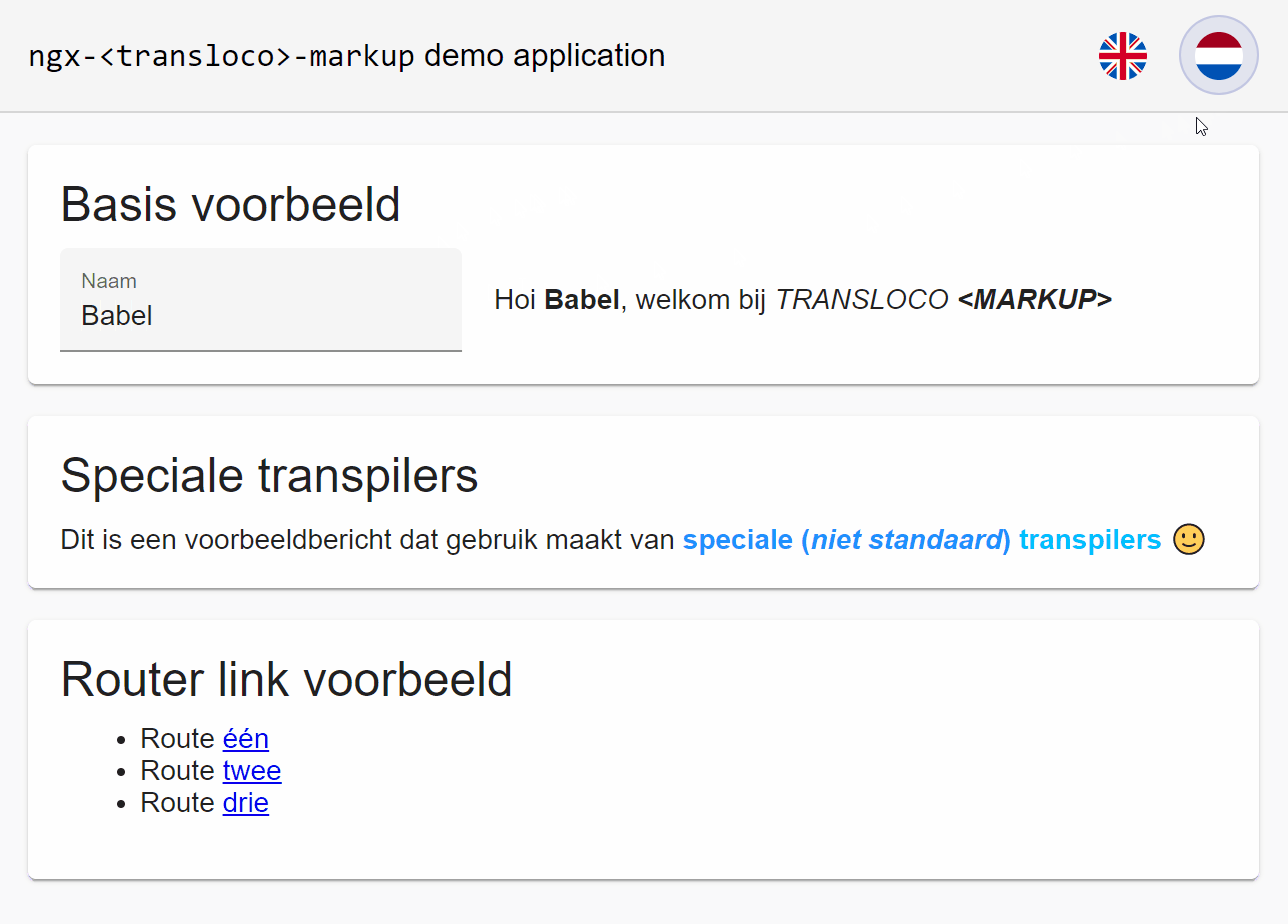
Summary
Preparing an application for internationalization often includes adding support for multiple languages. For Angular applications, several solutions (libraries) are available that enable you to quickly get up and running. Two popular translation libraries for Angular are NGX-Translate and Transloco.
Unfortunately, none of these libraries properly address a common use case: displaying translated text that contains some form of markup. Examples of markup are bold text, links, and icons. In practice there are two approaches to support markup in combination with translations: translation splitting and innerHTML-binding. Both have some disadvantages that can make their use quite problematic.
The translation splitting approach comes at the cost of verbosity. Its main problem, however, is that it does not work for texts where the order of the segments may differ from language to language, resulting in incorrect markup or awkwardly formed sentences.
For these reasons, the innerHTML-binding is often favored. While on the surface it seems like a much better approach, it also has some serious issues. First, it can introduce security vulnerabilities. Although Angular does its best to protect you from those, it cannot eliminate all threats (as demonstrated earlier).
Another issue with this approach is that it can clutter the translations with HTML markup, thereby making the job for translators quite difficult and increasing the chance of translation/markup errors.
Finally, things like including router links are hard to achieve with the innerHTML-binding approach.
Since both approaches seem to suffer from several issues, this begs the question of whether there is an alternative approach. As it turns out, there actually is one! It comes in the form of introducing your own custom markup syntax for translation values. This syntax can be tailored per translation entry to make it context specific. The advantage of this approach is that it can greatly simplify the necessary markup syntax in translation values. Also, none of the issues of the other two approaches are present with the contextual markup approach.
One thing that makes this third method more difficult to use in practice is that there is no built-in support for it. A high-level approach of how this could be implemented was outlined in this article. At the base of this approach is a translation component that can render translation values containing contextual markup. The component itself delegates most of its work to parsers that are responsible for converting the translation value into rendering functions.
These concepts have been implemented in the ngx-transloco-markup library. As the name suggests it is an extension for the Transloco translation library for Angular that adds support for displaying translations that include markup. Usage of this extension can make certain aspects of internationalization a whole lot easier. A demonstration can be found at: https://stackblitz.com/edit/ngx-transloco-markup-demo.